
The Elastic Stack attempts to solve this problem by providing a single interface view into a heterogeneous network. The Elastic Stack consists of Elasticsearch, Logstash, and Kibana (ELK). It is a highly scalable and modular framework for ingesting, analyzing, storing and visualizing data.
Elasticsearch is an open-core platform (open source in the core components) for searching and analyzing an organization’s data in near real-time. It can be used in many different contexts but has gained popularity in network security as a SIEM tool. Security Onion includes ELK and other components from Elastic including:
- Beats – This is a series of software plugins that send different types of data to the Elasticsearch data stores.
- ElastAlert – This provides queries and security alerts based on user-defined criteria and other information from data in Elasticsearch. Alert notifications can be sent to a console, or email and other notification systems such as TheHive security incident response platform.
- Curator – This provides actions to manage Elasticsearch data indices.
Elasticsearch, which is the search engine component, uses RESTful web services and APIs, a distributed computing cluster with multiple server nodes, and a distributed NoSQL database made up of JSON documents. Additional functionality can be added through custom-created extensions.
The Elasticsearch company offers a commercial extension called X-Pack which adds security, alerting, monitoring, reporting, and graphs. The company also offers a machine-learning add-on as well as their own Elastic SIEM product.
Logstash enables the collection and normalization of network data into data indexes that can be efficiently searched by Elasticsearch. Logstash and Beats modules are used to ingest data into the Elasticsearch cluster.
Kibana provides a graphical interface to data that is compiled by Elasticsearch. It enables visualization of network data and provides tools and shortcuts for querying that data in order to isolate potential security breaches.
The core open source components of the Elastic Stack are Logstash, Beats, Elasticsearch, and Kibana, as shown in the figure.
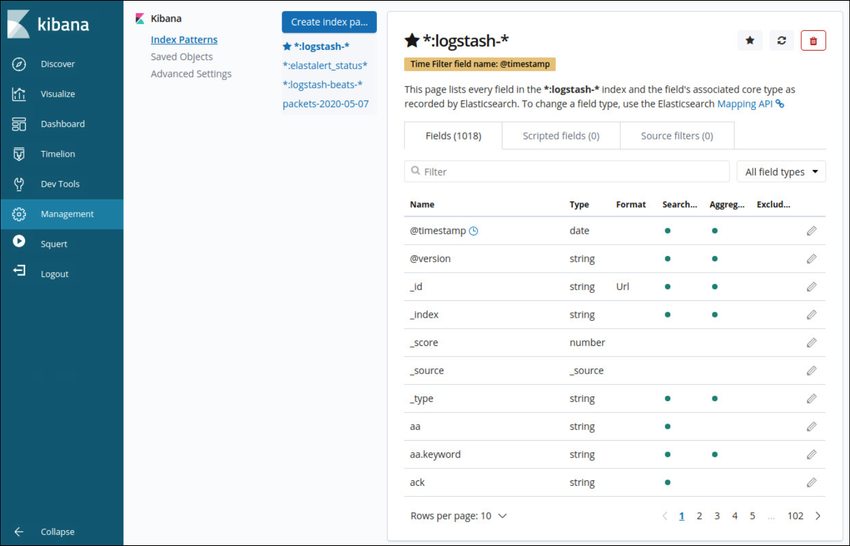
Logstash is an extract, transform and load the system with the ability to take in various sources of log data and transform or parse the data through translation, sorting, aggregating, splitting, and validation. After transforming the data, the data is loaded into the Elasticsearch database in the proper file format. The figure shows some of the fields that are available in Logstash as shown in the Kibana Management interface.
Kibana Management Frame Showing Logstash Index Details
Beats agents are open source software clients used to send operational data directly into Elasticsearch or through Logstash. Elastic, as well as the open-source community, actively develop Beats agents, so there are a huge variety of Beats agents for sending data to Elasticsearch in near real-time.
Elasticsearch is a cross-platform enterprise search engine written in Java. The core components are open-source with commercial addons called X-packs that give additional functionality. Elasticsearch supports near real-time search using simple REST APIs to create or update JavaScript Object Notation (JSON) documents using HTTP requests. Searches can be made using any program capable of making HTTP requests such as a web browser, Postman, cURL, etc. These APIs can also be accessed by Python or other programming language scripts for automated operations.
| MySQL Component: | database | tables | columns/rows |
| Elasticsearch Component: | index | types | documents |
Kibana provides an easy to use graphical user interface for managing Elasticsearch. By using a web browser, an analyst can use the Kibana interface to search and view indices.
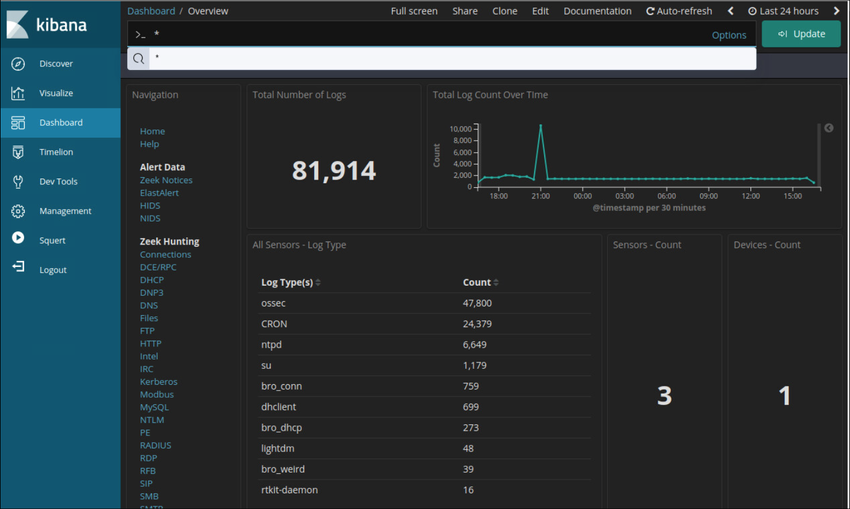
A Kibana Dashboard
Data Reduction
Some network traffic has little value to NSM.
In addition, alerts that are generated by a HIDS, such as Windows security auditing or OSSEC, should be evaluated for relevance.
Data Normalization
IPv6 Address Formats
- 2001:db8:acad:1111:2222::33
- 2001:DB8:ACAD:1111:2222::33
- 2001:DB8:ACAD:1111:2222:0:0:33
- 2001:DB8:ACAD:1111:2222:0000:0000:0033
MAC Formats
- A7:03:DB:7C:91:AA
- A7-03-DB-7C-91-AA
- A70.3DB.7C9.1AA
Date Formats
- Monday, July 24, 2017 7:39:35pm
- Mon, 24 Jul 2017 19:39:35 +0000
- 2017-07-24T19:39:35+00:00
- 1500925254
Data Archiving
Sguil alert data is retained for 30 days by default. This value is set in the securityonion.conf file.
Note: The storage locations for the different types of Security Onion data will vary based on the Security Onion implementation.
PS: If you would like to have an online course on any of the courses that you found on this blog, I will be glad to do that on an individual and corporate level, I will be very glad to do that I have trained several individuals and groups and they are doing well in their various fields of endeavour. Some of those that I have trained includes staffs of Dangote Refinery, FCMB, Zenith Bank, New Horizons Nigeria among others. Please come on Whatsapp and let’s talk about your training. You can reach me on Whatsapp HERE. Please note that I will be using Microsoft Team to facilitate the training.
I know you might agree with some of the points that I have raised in this article. You might not agree with some of the issues raised. Let me know your views about the topic discussed. We will appreciate it if you can drop your comment. Thanks in anticipation.
Fact Check Policy
CRMNAIJA is committed to fact-checking in a fair, transparent and non-partisan manner. Therefore, if you’ve found an error in any of our reports, be it factual, editorial, or an outdated post, please contact us to tell us about it.
|
